Pro 旗舰级定价完全一致,标准级小米凭多模态实现差异化优势
小米 5 月 27 日降价与 DeepSeek 5 月 22 日宣布的永久降价!!!
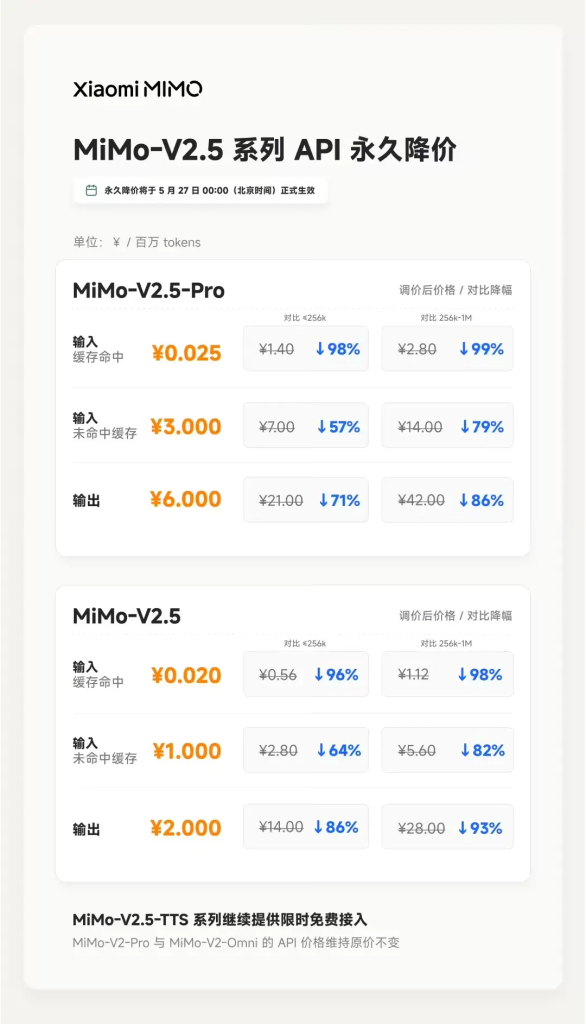
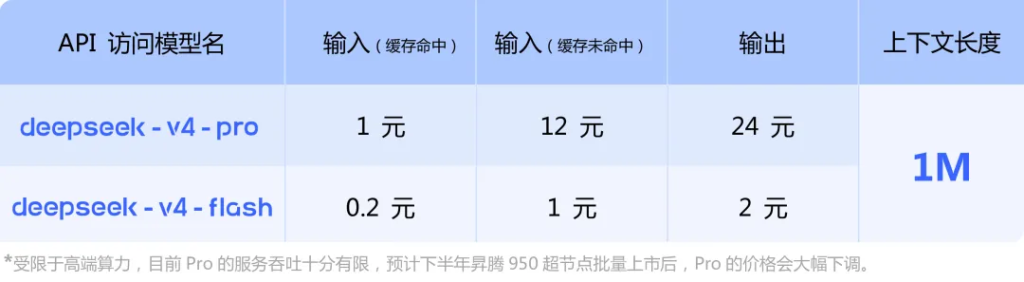
一、降价后完整定价对比
| 计费项 | MiMo-V2.5-Pro | DeepSeek V4-Pro | MiMo-V2.5(标准版) | DeepSeek V4-Flash |
|---|
| 输入(缓存命中) | 0.025 元 | 0.025 元 | 0.020 元 | 0.02 元 |
| 输入(缓存未命中) | 3 元 | 3 元 | 1 元 | 1 元 |
| 输出 | 6 元 | 6 元 | 2 元 | 2 元 |
| 上下文窗口 | 1M | 1M | 1M | 1M |
| 多模态 | 纯文本 | 纯文本 | 图像/音频/视频 | 纯文本 |
| 开源协议 | MIT | MIT | MIT | MIT |
数据来源:MiMo 官方调价公告 DeepSeek 官方定价页
两个层级的定价几乎完全镜像:Pro 级别三项单价完全一致,标准/Flash 级别也完全一致。但这里有一个关键差异——MiMo-V2.5 标准版是原生全模态模型(支持图像、音频、视频理解),而 DeepSeek V4-Flash 只是轻量级纯文本模型。同样的价格,小米给了多模态能力。
二、小米独有的成本优化机制
Token Plan 计费体系升级是小米本次降价的隐性加分项,很容易被忽略:
- 同等价格下可用 tokens 提升至原方案的 5-8 倍
- 引入 Credits 统一计量,计费规则”所见即所得”
- 所有有效期内的 Token Plan 用户 Credits 于 5 月 27 日 0:00 全量重置
- 北京时间 00:00~08:00 期间,所有模型 Credits 消耗速率再打 8 折
这意味着如果你使用 Token Plan 订阅制,小米的实际单位成本还会进一步降低。DeepSeek 目前没有同等规模的订阅优惠体系。
上下文窗口不再区分定价也是重要改进。此前小米对 256K 以上的长上下文窗口收取双倍价格,现在一律同价,这对 Agent 场景(经常需要长上下文)是直接利好。
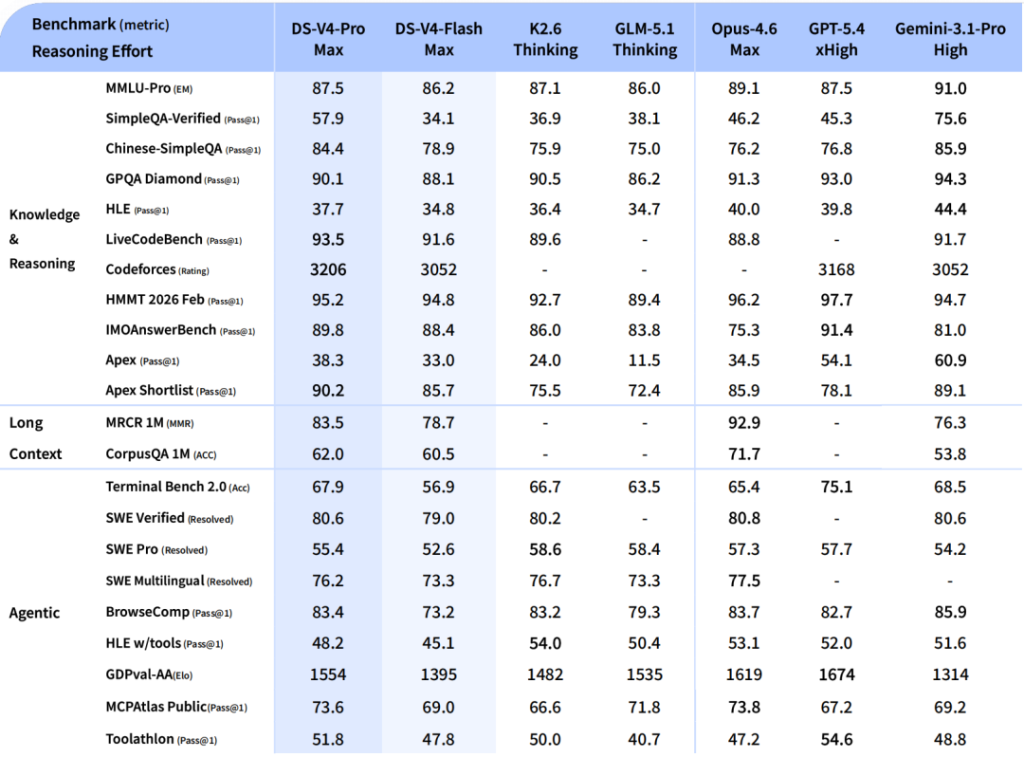
三、性能与能力对比
根据独立第三方 Artificial Analysis Intelligence Index v4.0(截至 2026 年 5 月 6 日)的数据:
| 评测维度 | MiMo-V2.5-Pro | DeepSeek V4-Pro | 优势方 |
|---|
| AA Intelligence Index | 54 分(并列开源第 1) | 52 分(并列第 2) | MiMo |
| GDPval-AA Agent | 并列开源第 1 | 并列开源第 1 | 持平 |
| ClawEval(长程 Agent) | 63.8% | 59.8% | MiMo |
| τ³-bench(跨任务协作) | 72.9% | 71.8% | MiMo |
| SWE-bench Verified | 78.9% | 80.6% | DeepSeek |
| SWE-bench Pro(复杂工程) | 57.2% | 55.4% | MiMo |
| LiveCodeBench Pass@1 | — | 93.5% | DeepSeek |
| Codeforces Rating | — | 3206(人类第 23) | DeepSeek |
| Terminal-Bench 2.0 | 68.4% | 67.9% | MiMo |
| 幻觉率(AA-Omniscience) | 暂无数据 | 94%(极高) | MiMo 无数据但 DS 确认高 |
数据来源:CSDN 技术博客 搜狐
Token 效率是 MiMo 的重要差异化优势。MiMo-V2.5-Pro 在 Agent 长程任务中比 Kimi K2.6 节省约 42% Token,在 ClawEval 评测中比 Claude Opus 4.6、Gemini 3.1 Pro 节省 40%~60%。由于 Agent 任务 token 消耗指数级增长,省 token 直接等于省真金白银——在相同定价下,MiMo 完成同等任务的实际花费更低。
四、场景化性价比结论
场景 1:Agent 自动化与长程工作流(多步工具调用、代码工程 Agent)
推荐 MiMo-V2.5-Pro。Agent 能力在第三方评测中领先,Token 效率更高意味着实际成本更低,响应速度更快。小米取消上下文窗口差异化定价后,Agent 场景的长上下文调用不再有价格惩罚。
场景 2:竞赛编程与深度数学推理
推荐 DeepSeek V4-Pro。LiveCodeBench 93.5% 和 Codeforces 3206 分是开源最强,思考时间更长但推理深度更深。不过需要注意 94% 的幻觉率在可靠性要求高的场景中是硬伤。
场景 3:多模态任务(图像理解、音视频处理、办公自动化)
推荐 MiMo-V2.5(标准版)。DeepSeek V4 全系为纯文本模型,而 MiMo-V2.5 标准版原生支持图像/音频/视频理解,输出价格仅 2 元/百万 tokens,同等价位下 DeepSeek V4-Flash 只能处理文本。
场景 4:高频轻量调用与批量处理
MiMo-V2.5 标准版与 DeepSeek V4-Flash 定价完全相同(0.02 / 1 / 2),但 MiMo-V2.5 多模态能力覆盖更广,且 Token Plan 订阅可进一步压低成本。如果纯文本且高频调用,V4-Flash 也是可靠选择。
场景 5:订阅制与大用量部署
MiMo 占优。Token Plan 体系下同等价格可用 tokens 提升 5~8 倍,加上凌晨 8 折优惠和 Credits 全量重置,大规模部署的实际单位成本显著低于按量计费的 DeepSeek。
五、总结判断
在 Pro 级别,两家定价完全相同,性价比之争完全回归到能力差异:MiMo-V2.5-Pro 综合评分更高(54 vs 52),Agent 和 Token 效率领先;DeepSeek V4-Pro 在纯编程和数学推理上更强,但幻觉率是重大隐患。
在标准级,同样是相同定价,但 MiMo-V2.5 标准版凭多模态能力实现了真正的差异化——同样的 2 元输出价格,小米给的是图像/音频/视频全模态模型,DeepSeek V4-Flash 只是轻量纯文本模型。
叠加 Token Plan 5~8 倍加量、取消上下文窗口差异化定价、凌晨 8 折等优惠机制,小米 MiMo-V2.5 系列在整体性价比上略胜一筹,尤其对于 Agent 场景、多模态需求和订阅制用户。但如果你是竞赛编程或需要极致数学推理深度的用户,DeepSeek V4-Pro 仍然是更专业的工具。