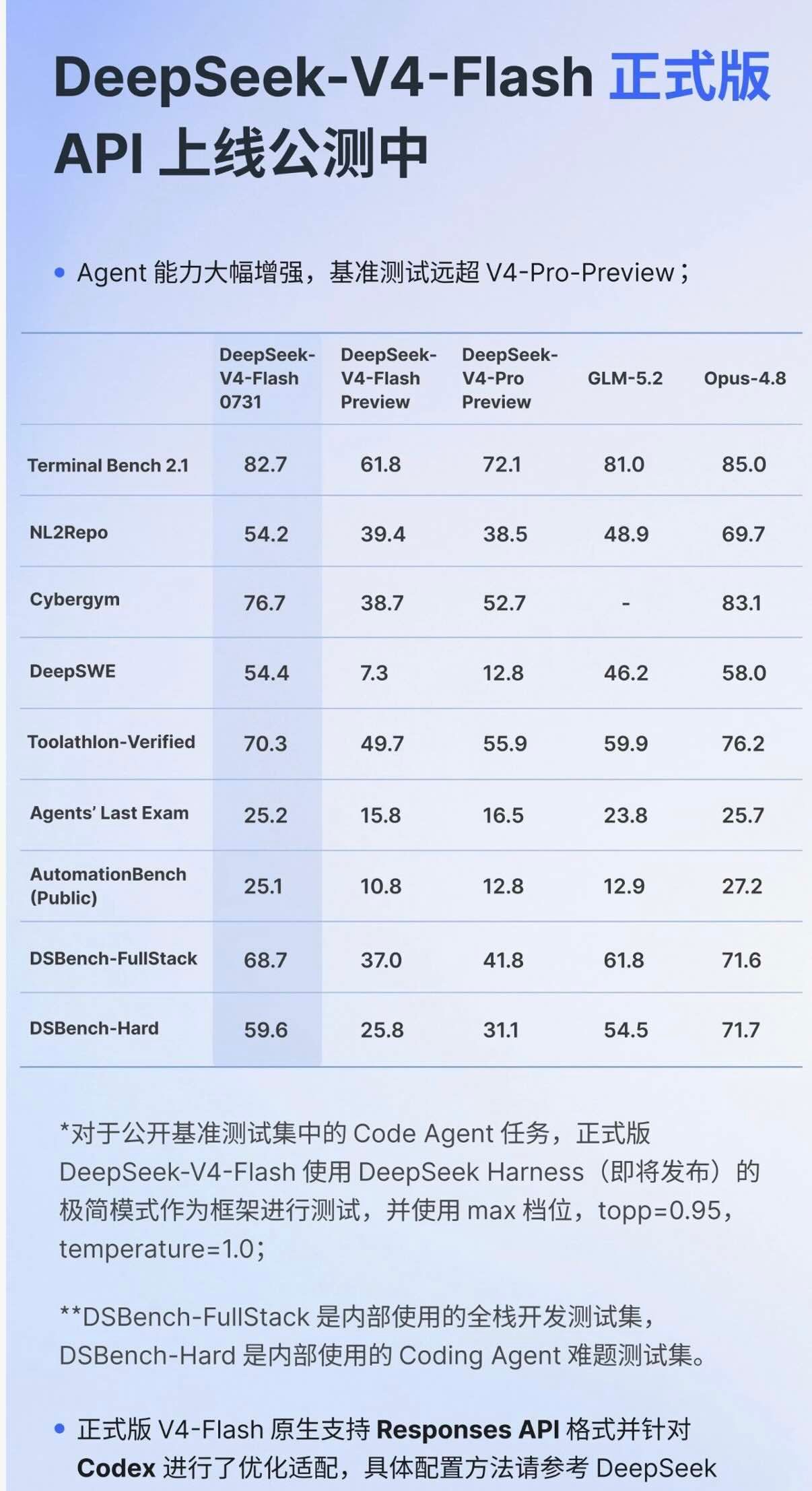
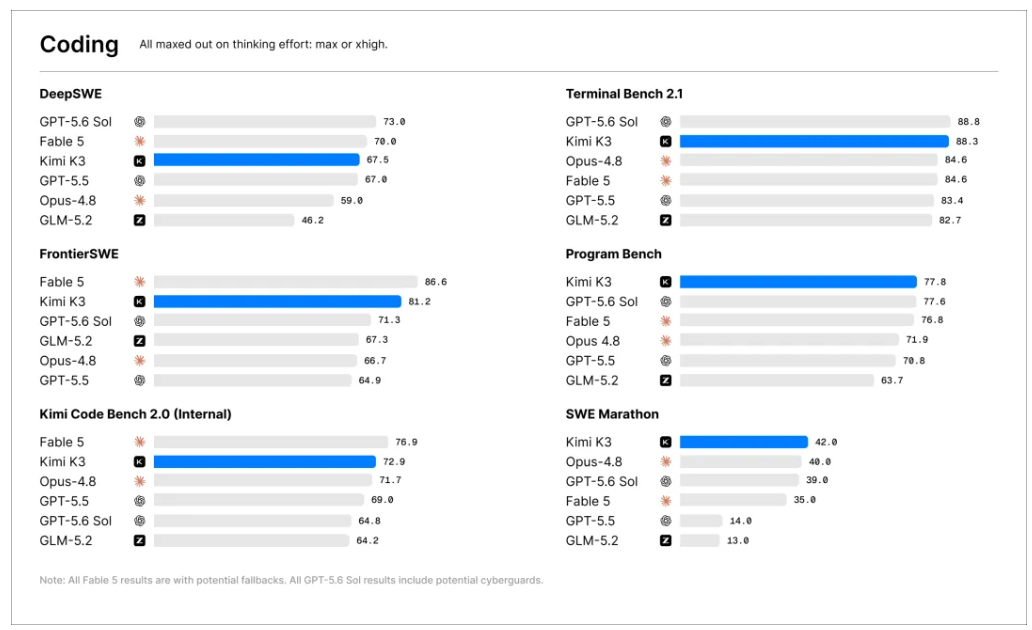
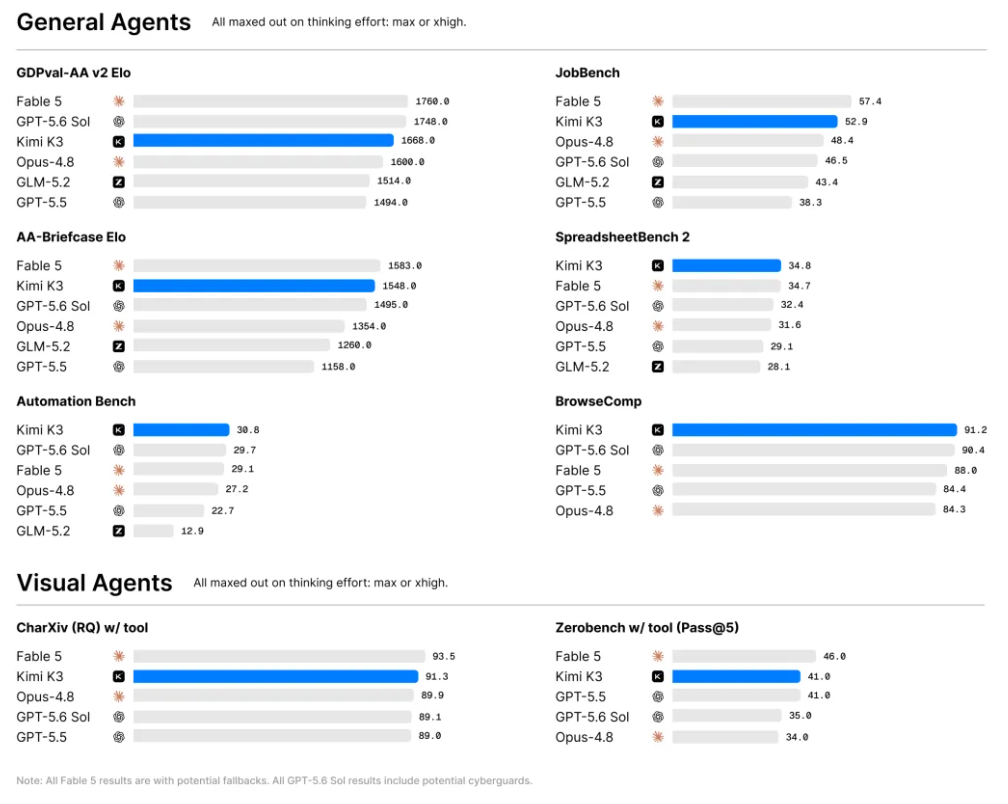
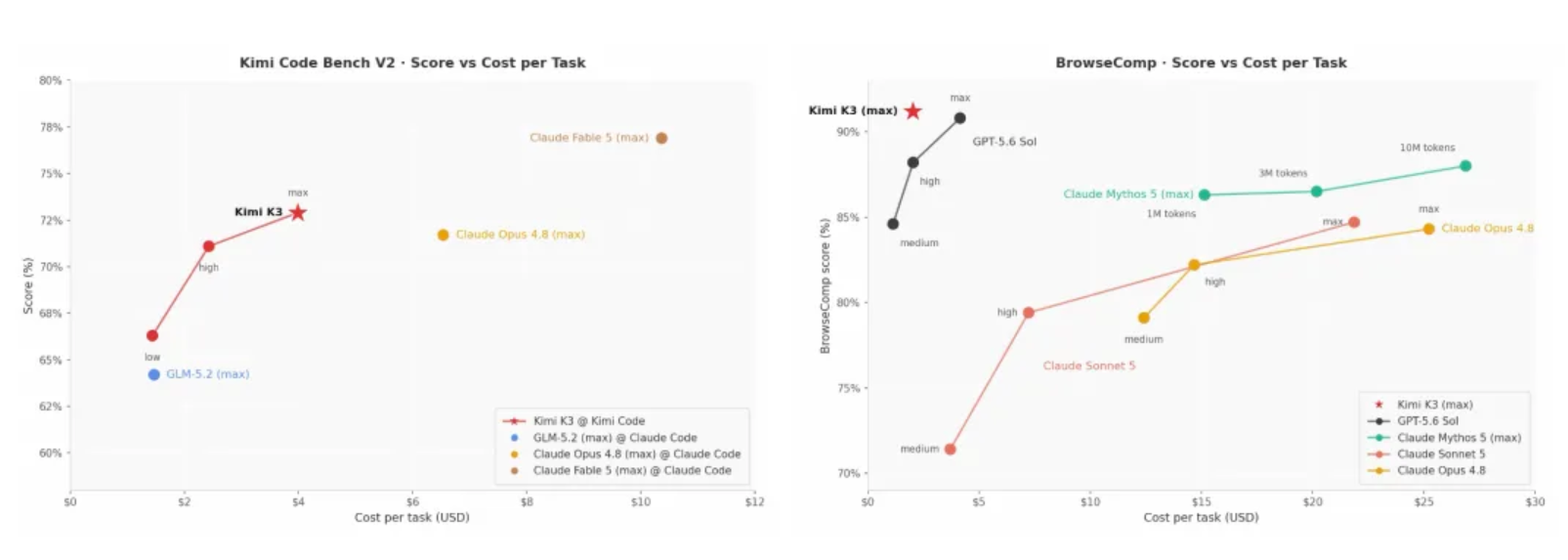
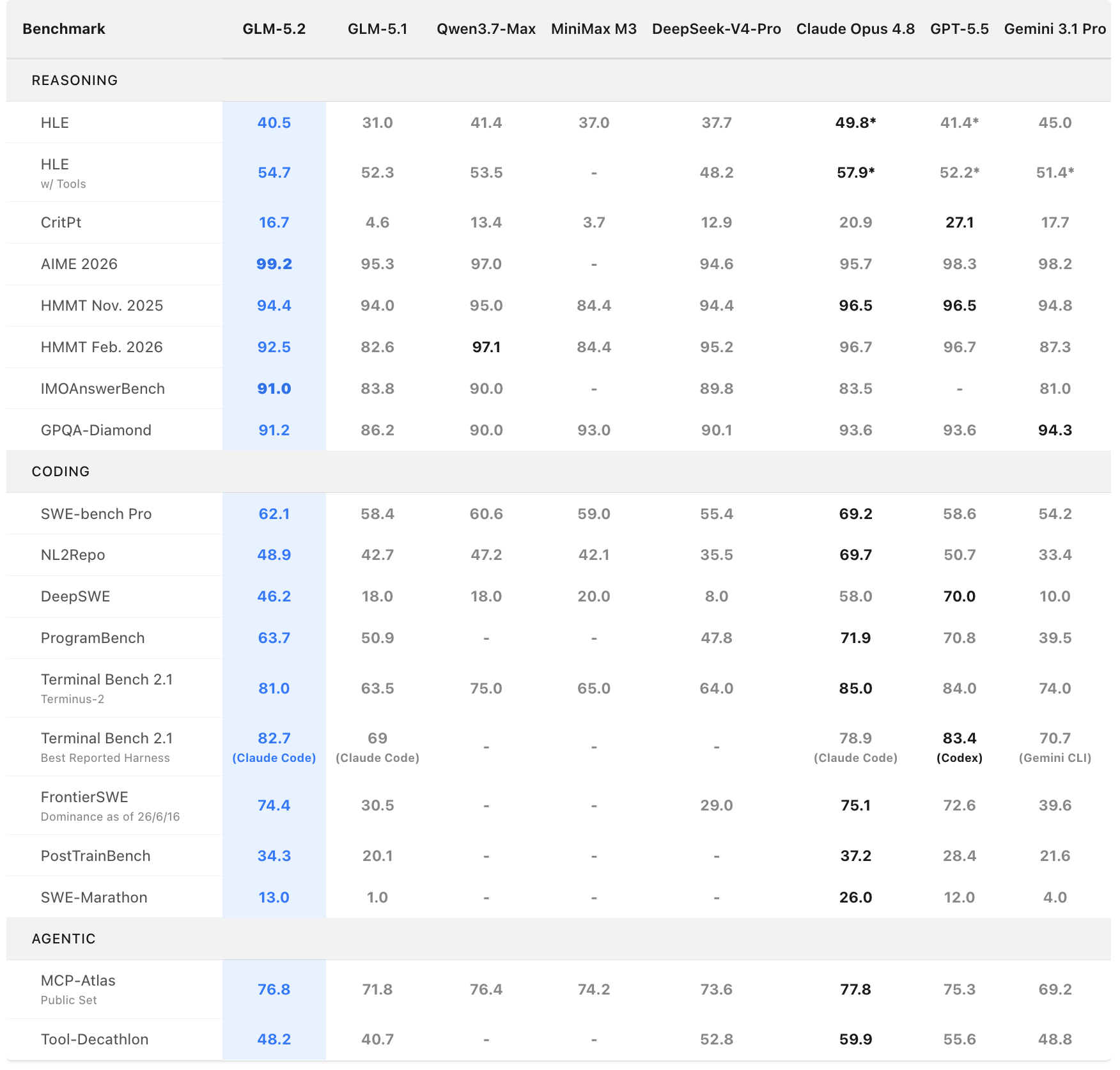
Terminal-Bench 2.1 上 81.0 的成绩距离 Claude Opus 4.8 的 85.0 仅差 4 分,而 Gemini 3.1 Pro 已被甩在身后。
GLM-5.2 引入的 effort level 控制是一大亮点。在同等 token 预算下,GLM-5.2 的 Agent 编程能力显著强于 GLM-5.1,能力定位大致介于 Claude Opus 4.7 和 Opus 4.8 之间。当你遇到高难度任务时,切换到 Max 力度级别可分配更多计算资源,换取更高性能。
[postgres@pg01 tools]$ pg_basebackup -h 10.0.0.101 -U postgres -F p -P -X stream -R -D $PGDATA -l postgresbackup20260616
2026-06-16 10:17:31.017 CST [1577] FATAL: no pg_hba.conf entry for replication connection from host "10.0.0.101", user "postgres"
pg_basebackup: error: could not connect to server: FATAL: no pg_hba.conf entry for replication connection from host "10.0.0.101", user "postgres"
明明 pg_hba.conf 里已经配置了 all 规则,为什么还会被拒绝?
二、问题原因
pg_basebackup 走的是 replication 连接,而 replication 并不是一个真实的数据库,它是一个虚拟库。pg_hba.conf 中的 host all all ... 规则只覆盖普通数据库连接,不覆盖 replication 连接。