
书籍是屹立在时间的汪洋大海中的灯塔。
迷茫时,书是指点你的名师
失意时,书是鼓励你的朋友
痛苦时,书是疗愈你的良医
过度依赖AI或导致损坏批判性思维与记忆力
用 AI 会让人变笨,过度依赖 AI 或导致损坏批判性思维与记忆力
由麻省理工学院媒体实验室的 Nataliya Kosmyna 及其团队主导的最新研究,深入探讨了在论文写作任务中,使用大型语言模型(LLM)如 OpenAI 的 ChatGPT 可能带来的认知成本。该研究发现,尽管 LLM 产品为人类和企业带来了诸多便利,但其广泛应用却可能导致大脑积累 “认知负债”,长远来看甚至会削弱个体的学习技能
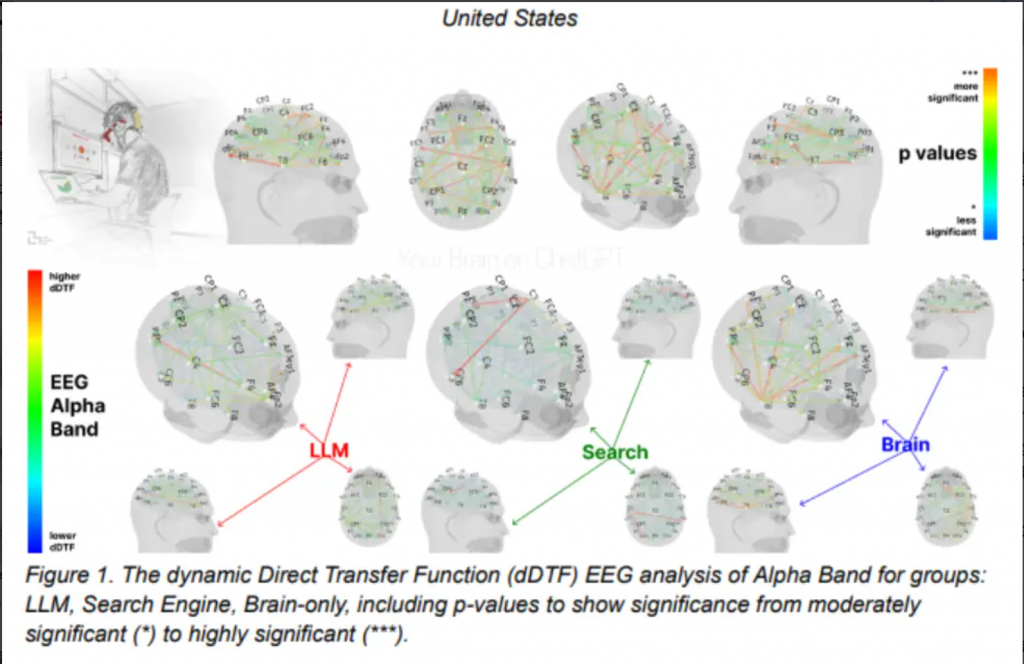
该研究招募54名参与者,并将其分为三组:LLM 组(仅使用 ChatGPT)、搜索引擎组 (使用传统搜索引擎,禁用 LLM) 和纯脑力组 (不使用任何工具)。研究共进行了四次会话,其中在第四次会话中,LLM 组的参与者被要求不使用任何工具 (被称为 “LLM 转纯脑力组”),而纯脑力组的参与者则开始使用 LLM (被称为 “纯脑力转 LLM 组”)。
研究团队通过脑电图 (EEG) 记录了参与者的大脑活动,以评估其认知投入和负荷,并深入理解论文写作任务期间的神经激活模式。此外,研究还进行了自然语言处理 (NLP) 分析,并在每次会话后对参与者进行了访谈,同时邀请人类教师和 AI 评判员对论文进行打分。
核心发现:大脑连接性减弱,记忆和所有权受损
研究结果提供了确凿证据,表明 LLM、搜索引擎和纯脑力组的神经网络连接模式存在显著差异,反映了不同的认知策略。大脑连接性与外部支持的程度呈系统性下降:纯脑力组表现出最强、范围最广的连接网络,搜索引擎组居中,而 LLM 辅助则引发了最弱的整体耦合。
特别值得关注的是,在第四次会话中,“LLM 转纯脑力组” 的参与者表现出较弱的神经连接性,以及阿尔法(alpha)和贝塔 (beta) 网络的投入不足。阿尔法波段连接性通常与内部注意力、语义处理和创造性构思相关。贝塔波段则与主动认知处理、专注注意力和感觉运动整合相关。这些结果表明,过去依赖 LLM 的使用者,在脱离工具后,其大脑在内容规划和生成方面的神经活动有所减少,这与认知卸载的报告相符,即依赖 AI 系统可能导致被动方法和批判性思维能力的减弱。
在记忆方面,LLM 组的参与者在引用自己刚写完的论文时表现出明显障碍,甚至无法正确引用。这直接映射到 LLM 组较低的低频连接性,特别是与情景记忆巩固和语义编码密切相关的西塔(theta)和阿尔法波段。这表明 LLM 用户可能绕过了深层记忆编码过程,被动地整合了工具生成的内容,而没有将其内化到记忆网络中。
此外,LLM 组对自己论文的所有权感知度普遍较低,而搜索引擎组拥有较强的所有权感,但仍低于纯脑力组。这种行为上的差异与神经连接性模式的变化相吻合,凸显了 LLM 使用对认知能动性的潜在影响。
认知负债的积累:效率与深度学习的权衡
研究指出,尽管 LLM 在初期提供了显著的效率优势并降低了即时认知负荷,但随着时间的推移,这种便利可能以牺牲深度学习成果为代价。报告强调了 “认知负债” 的概念:重复依赖外部系统(如 LLM)取代了独立思考所需的努力认知过程,短期内延迟了脑力投入,但长期却导致批判性探究能力下降、更容易被操纵以及创造力减退。
纯脑力组的参与者,尽管面临更高的认知负荷,却展现出更强的记忆力、更高的语义准确性和对其作品更坚定的主人翁意识。而 “纯脑力转 LLM 组” 在首次使用 AI 辅助重写论文时,大脑连接性显著增加,这可能反映了将 AI 建议与现有知识整合时的认知整合需求,暗示了 AI 工具引入的时机可能对神经整合产生积极影响。
对教育环境的深远影响与未来展望
研究团队认为,这些发现对教育领域具有深远意义。过度依赖 AI 工具可能无意中阻碍深层认知处理、知识保留以及对书面材料的真实投入。如果用户过度依赖 AI 工具,他们可能会获得表面的流畅度,但却无法内化知识或对其产生所有权感。
该研究建议,教育干预应考虑将 AI 工具辅助与 “无工具” 学习阶段相结合,以优化即时技能转移和长期神经发展。在学习的早期阶段,全面的神经参与对于发展强大的写作网络至关重要;而在后续练习阶段,有选择性的 AI 支持可以减少无关的认知负荷,从而提高效率,同时不损害已建立的网络。
研究人员强调,随着 AI 生成内容日益充斥数据集,以及人类思维与生成式 AI 之间的界限变得模糊,未来研究应优先收集不借助 LLM 协助的写作样本,以发展能够识别作者个人风格的 “指纹” 表示。
最终,这项研究呼吁在 LLM 整合到教育和信息情境中时,必须谨慎权衡其对认知发展、批判性思维和智力独立性的潜在影响。LLM 虽然能减少回答问题的摩擦,但这种便利性也带来了认知成本,削弱了用户批判性评估 LLM 输出的意愿。这预示着 “回音室” 效应正在演变,通过算法策划内容来塑造用户接触信息的方式。
(研究论文标题为《Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task》,主要作者为麻省理工学院媒体实验室的 Nataliya Kosmyna 等。)
双重否定式
假如我们不是深信自己对别国领土和财富没有贪婪的恶念,没有攫取物资的野心,没有卑鄙的念头,那么我们在今年的圣诞节中,一定会很难过。
因为我们深信自己对别国毫无恶念,所以圣诞节才能过得心安理得(不难过)。
假如我们不是深信自己对别国毫无恶念,那么我们在圣诞节一定会很难过。
硬盘性能测试
mkdir test-data
fio –rw=write –ioengine=sync –fdatasync=1 –directory=test-data –size=2200m –bs=2300 –name=mytest
命令分解
mkdir test-data # 创建测试目录
fio \
--rw=write # 测试模式:纯写入
--ioengine=sync # I/O引擎:同步阻塞写入(模拟最严苛的持久化场景)
--fdatasync=1 # 每次写入后调用fdatasync(),确保数据刷到磁盘(类似数据库安全写入)
--directory=test-data # 测试目录
--size=2200m # 每个线程写入总量:2200MB
--bs=2300 # 块大小:2300字节(模拟非常规小块写入)
--name=mytest # 任务名称关键参数作用
| 参数 | 意义 | |
|---|---|---|
--rw=write | 测试写入性能(非随机写入)。 | |
--ioengine=sync | 使用同步I/O,每次写操作必须等待磁盘确认完成(性能低但数据安全)。 | |
--fdatasync=1 | 每次写操作后调用 fdatasync(),强制刷新内核缓冲区到磁盘(类似 fsync 但略轻量)。 | |
--bs=2300–size=2200m | 设置非常规块大小(通常用4K/8K),可能是为了模拟特定业务场景的小数据块写入。 总写入量足够大,避免缓存影响测试结果。 |
典型应用场景
- 数据库持久化测试
- 模拟事务日志(如WAL)的写入性能,因为
sync+fdatasync是数据库保证ACID的常用配置。
- 磁盘可靠性验证
- 测试磁盘在强制刷盘模式下的实际吞吐和延迟。
- 性能调优基准
- 对比不同文件系统/磁盘设备在小块同步写入时的表现。
输出结果关注点
运行后会显示以下关键指标:
- IOPS:每秒写入次数(2300字节/次)。
- 带宽(BW):实际写入吞吐(如 MB/s)。
- 延迟(lat):每次写入的平均耗时(尤其关注
sync和fdatasync的开销)。
示例输出片段:
write: IOPS=500, BW=1.12MiB/s (1.17MB/s)
sync (usec): min=100, max=10000, avg=2000
fdatasync: 1 calls, total=10ms注意事项
- 磁盘压力:此命令会高负载写入,避免在生产环境直接运行。
- 块大小优化:
bs=2300可能导致未对齐写入,正常测试建议用4K的整数倍。 - 对比测试:移除
--fdatasync=1和--ioengine=sync可测试缓存写入性能(速度会快很多)。
智谱最新的模型
GLM-Z1-AirX(极速版):定位国内最快推理模型,推理速度可达 200 tokens / 秒,比常规快 8 倍;
GLM-Z1-Air(高性价比版):价格仅为 DeepSeek-R1 的 1/30,适合高频调用场景;
GLM-Z1-Flash(免费版):支持免费使用,旨在进一步降低模型使用门槛。
佛洛依德冰山理论
“本我” 代表欲望,受意识遏抑, (完全潜意识)
“自我” 负责处理现实世界的事情; (大部分有意识)
“超我” 是良知或内在的道德判断。 (部分有意识)
豆包代写的代码
import requests
import json
import sys
url = 'http://x.x.x.x/v1/chat-messages'
headers = {
'Authorization': 'Bearer app-KT4yNocX6Bzey6mZ5Jxxxx',
'Content-Type': 'application/json'
}
conversation_id = ""
while True:
try:
# 获取系统默认编码
encoding = sys.getdefaultencoding()
query = input("请输入你的问题(输入 '退出' 结束对话):").encode(encoding).decode(encoding)
if query == "退出":
break
data = {
"inputs": {},
"query": query,
"response_mode": "streaming",
"conversation_id": conversation_id,
"user": "ts",
"files": [
{
"type": "image",
"transfer_method": "remote_url",
"url": "https://cloud.dify.ai/logo/logo-site.png"
}
]
}
try:
response = requests.post(url, headers=headers, json=data, stream=True)
response.raise_for_status()
full_response = []
full_api_response = []
for chunk in response.iter_lines(decode_unicode=True):
if chunk.startswith('data:'):
chunk_data = chunk[5:].strip()
if chunk_data:
full_api_response.append(chunk_data)
try:
event = json.loads(chunk_data)
if event.get('event') == 'message':
answer = event.get('answer', '')
print(answer, end='', flush=True)
full_response.append(answer)
elif event.get('event') == 'message_end':
print()
final_answer = ''.join(full_response)
print(f"完整回复: {final_answer}")
conversation_id = event.get('conversation_id', conversation_id)
except json.JSONDecodeError:
print(f"解析错误: {chunk_data}")
print("\nAPI 接口返回的完整信息:")
for line in full_api_response:
print(line)
except requests.exceptions.RequestException as e:
print(f"请求错误: {e}")
except UnicodeDecodeError:
print("输入解码时出现错误,请检查终端编码设置。")
su 与 su – 切换root变量
[ceshizhangzhao@ceshizhangzhao1 ~]$ whoami #确认当前用户为ceshizhangzhao root
ceshizhangzhao
[ceshizhangzhao@ceshizhangzhao1 ~]$ su #不加用户就表示切换到root,当然也可以su root root
Password:
[root@ceshizhangzhao1 ceshizhangzhao]# env
HOSTNAME=ceshizhangzhao1
SHELL=/bin/bash
HISTSIZE=500
USER=ceshizhangzhao <--
MAIL=/var/spool/mail/ceshizhangzhao
PWD=/home/ceshizhangzhao <--
HOME=/root
LOGNAME=ceshizhangzhao
以下省略无关内容…
提示:使用su而不加上“-”这个参数,切换前的用户的相关信息还会存在。切换用户时,“su - 用户名”。
[root@ceshizhangzhao1 ceshizhangzhao]# exit #退出当前用户,这个命令也可以用ctrl+d
[ceshizhangzhao@ceshizhangzhao1 ~]$ su - root
Password:
[root@ceshizhangzhao1 ~]# env | egrep "USER|MALL|PWD|LOGNAME"
USER=root <--
PWD=/root <--
LOGNAME=root
总结:请su –
人生的感悟
一花一一花一木一世界,一朝一夕一浮生,一生一世一轮回。一悲一喜一枯荣,一真一假一尘缘,一起一落一平生。 一直一念一徒然,一心一念一清净,一梦一醒一凡尘。
定期清理日志
!/bin/bash
设置变量
LOG_DIR="/a/b/c" # 替换为实际的日志目录
ARCHIVE_DIR="/a/b/c/history_archive" # 替换为存储归档的目录
DAYS_TO_KEEP=30 # 保留日志的天数
LOG_FILE="/a/b/c/history_archive/op_record.log" # 替换为实际的日志文件路径
创建归档目录(如果不存在)
mkdir -p "$ARCHIVE_DIR"
获取当前日期
CURRENT_DATE=$(date +%Y-%m-%d)
记录开始时间
echo "[$CURRENT_DATE] 开始压缩和归档日志…" >> "$LOG_FILE"
压缩并归档日志
for dir in "$LOG_DIR"/20*; do
if [ -d "$dir" ]; then
# 获取目录名
dir_name=$(basename "$dir")
# 压缩目录 tar -zcf "$ARCHIVE_DIR/${dir_name}.tar.gz" -C "$LOG_DIR" "$dir_name" # 检查压缩是否成功 if [ $? -eq 0 ]; then echo "[$CURRENT_DATE] 已压缩并归档: $dir_name" >> "$LOG_FILE" # 删除原始日志目录 rm -rf "$dir" echo "[$CURRENT_DATE] 已删除原始日志目录: $dir_name" >> "$LOG_FILE" else echo "[$CURRENT_DATE] 压缩失败: $dir_name" >> "$LOG_FILE" fi fi
done
清理超过指定天数的归档文件
find "$ARCHIVE_DIR" -type f -name "*.tar.gz" -mtime +$DAYS_TO_KEEP -exec rm -f {} \;
echo "[$CURRENT_DATE] 已删除超过 $DAYS_TO_KEEP 天的归档文件" >> "$LOG_FILE"
记录结束时间
echo "[$CURRENT_DATE] 完成压缩和归档日志." >> "$LOG_FILE"