
Z.ai 发布 GLM-5.2,1M 可用上下文 + 多级思考力度控制,开源模型首次挑战闭源旗舰长程任务能力
一、GLM-5.2 是什么
GLM-5.2 是 Z.ai 面向长程任务时代的旗舰模型。核心亮点是一个真正可用的 1M token 上下文窗口——不是在评测指标上好看,而是在真实的工程场景中能稳定工作。它能在单次任务中处理项目级别的工程上下文、可靠执行长时间运行的任务、一致性遵循工程规范,并且完成从需求到多平台部署的完整开发工作流。
二、三大新特性
- Solid 1M 上下文:1M token 的前置上下文,能稳定支撑长程工作,不只是接受更多 token,而是在混乱的代码轨迹中保持质量。
- 多级思考力度控制:更强的编程能力,提供 High 和 Max 两个思考努力级别,让用户在性能、延迟和计算成本之间自由平衡。
- 纯粹开源:MIT 开源许可证——技术无国界。
三、长程任务能力:开源最强,紧追闭源旗舰
GLM-5.2 在三个长程编码基准测试中表现亮眼,全部位列开源模型第一:
| 基准测试 | 说明 | GLM-5.2 表现 | 排名 |
|---|---|---|---|
| FrontierSWE | 衡量 Agent 完成数小时到数十小时的开放式技术项目 | 落后 Opus 4.8 仅 1%,领先 GPT-5.5 1%,领先 Opus 4.7 11% | 开源第一,整体第二 |
| PostTrainBench | 给 Agent 一块 H100 GPU,评判其对小模型的后训练改进能力 | 超越 Opus 4.7 和 GPT-5.5 | 仅次于 Opus 4.8 |
| SWE-Marathon | 超长程任务,包括构建编译器、优化内核、开发生产级服务 | 落后 Opus 4.8 13% | 仅次于 Opus 系列 |
这三个基准的共性在于:它们测试的不是模型能接受多少 token,而是模型在数万 token 的真实工程轨迹中能否持续保持高质量输出——这正是 GLM-5.2 的 1M 上下文训练的落脚点。
四、更强编程能力:开源标杆
在标准编程基准上,GLM-5.2 大幅领先前代 GLM-5.1,并显著缩小了与闭源前沿的差距:
| 基准测试 | GLM-5.2 | GLM-5.1 | Claude Opus 4.8 | Gemini 3.1 Pro |
|---|---|---|---|---|
| Terminal-Bench 2.1 | 81.0 | 62.0 | 85.0 | 低于 GLM-5.2 |
| SWE-bench Pro | 62.1 | 58.4 | — | — |
Terminal-Bench 2.1 上 81.0 的成绩距离 Claude Opus 4.8 的 85.0 仅差 4 分,而 Gemini 3.1 Pro 已被甩在身后。
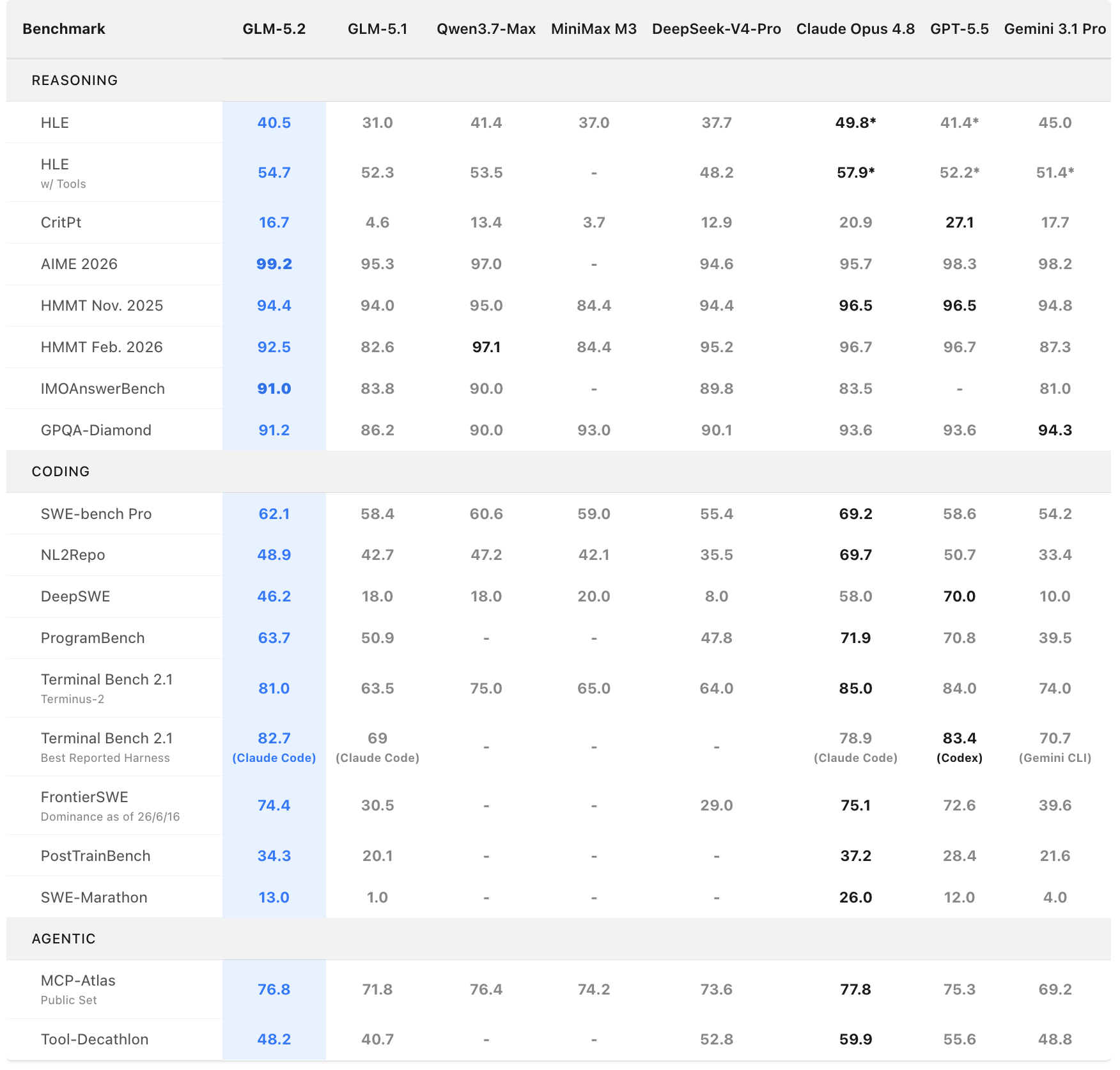
GLM-5.2 引入的 effort level 控制是一大亮点。在同等 token 预算下,GLM-5.2 的 Agent 编程能力显著强于 GLM-5.1,能力定位大致介于 Claude Opus 4.7 和 Opus 4.8 之间。当你遇到高难度任务时,切换到 Max 力度级别可分配更多计算资源,换取更高性能。
五、总结判断
GLM-5.2 是截至目前 开源模型在长程 Agent 任务上的最强选手。它的 1M 上下文不是噱头,而是在 FrontierSWE、PostTrainBench、SWE-Marathon 三个真实工程场景中验证过的能力。在标准编程能力上,它稳坐开源第一把交椅,并首次让开源模型与闭源旗舰的差距缩小到个位数百分比。
对于 AI Agent 开发者、长程自动化场景和需要高质量代码生成的团队,GLM-5.2 是目前开源阵营中最值得关注的选择。配合 MIT 开源协议和 Ollama 一键部署,上手几乎没有门槛。